When it comes to artificial intelligence’s power, data labeling has emerged as the most powerful aspect of helping improve machine learning models. But, have you ever thought about what exactly is Data Labeling and why it is so important? Well, we will delve a little deeper into the different concepts of Data Labelling and how it can be helpful in AI development.
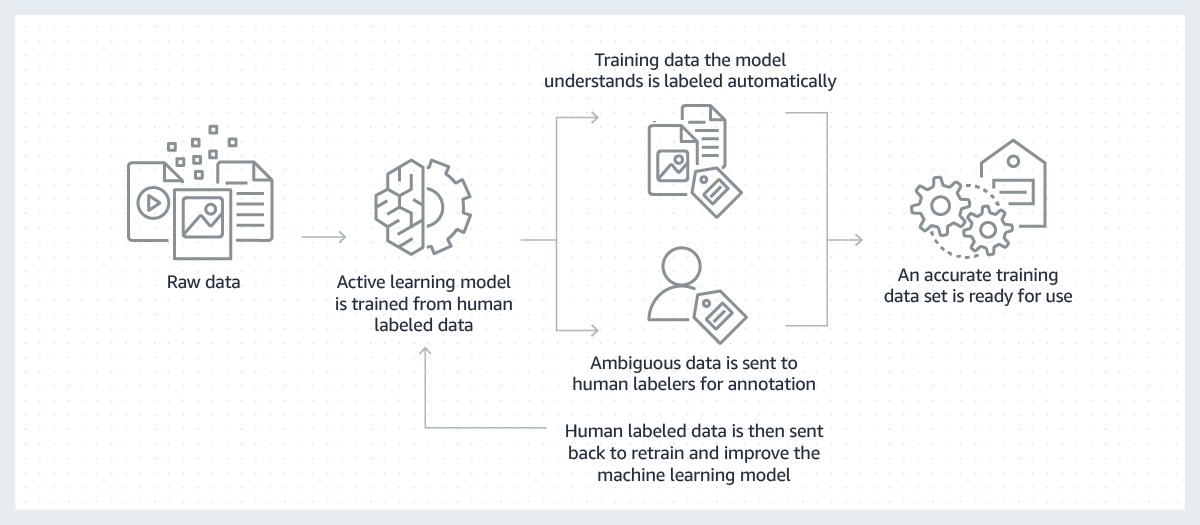
What is Data Labelling?
Data Labeling is a phase or step in machine learning. It involves identifying the different objects in terms of their raw data and tagging them with labels. This will further help the machine learning model to make accurate predictions through the use of these labels.
Data labeling is the first step in the task of training the machine learning models. The data labeling helps in adding the relevant context to the raw data and thus enables the algorithms to learn and make accurate predictions.
Why Is Data Labeling So Important?
Data Labeling assumes a lot of essence in providing an effective and efficient dataset for supervised data models. They assist the machine learning models in processing and understanding the input data more effectively.
Data Labelling can be effective in the following ways:
- Enhancing Machine Learning Models: Proper and effective data labeling can help the machine learning models in an improved level of performance. It acts as the foundation on which the entire machine-learning model rests.
- Ensuring Accuracy and Reliability: In today’s AI-enabled world, data reliability is of paramount importance. Proper and efficient data labeling can help machine learning models be more trustworthy.
Types of Data Labeling
Data Labeling typically belongs to three different types. Of course, there are a few other elements involved in effective data labeling.
Automated Data Labelling
Automated data labeling involves a lack of human effort in the task of tagging the raw data. In automated labeling, the focus is on reducing human efforts while maintaining the best possible accuracy. However, it needs the human labeler to validate and verify the Labelling.
Manual Data Labelling
This involves the entire data labeling by humans. It will help you enhance the accuracy as it comes with a nuanced accuracy in the data labeling process. It involves each set of data being labeled by the human labelers.
Semi-supervised learning
This involves a hybrid approach. It offers a combination of both automated and manual learning. It can provide you with a good combination of precision and efficiency.
Use Cases of Data Labelling
Data Labelling has been known to be a perfect option in several real-life scenarios. Some of them may include:
Challenges You May Face in Data Labelling
The challenges in data labeling can be multifaceted. But, they can severely affect the quality and efficiency of the machine learning models.
Best Practices in Data Labelling
The best way to get the best out of your data labeling exercises and ensure that they are accurate, reliable, and consistent is to employ the best practices in data labeling.
Some of the best practices that you can employ include:
The Future of Data Labelling
Looking into the future, Data Labelling does come with significant transformation and advancements. The expertise offered by the technological innovations should definitely prove to be quite innovative in every respect. The focus on the emerging trends in artificial intelligence should further prove to be quite an excellent option in the right direction.
Ethical Considerations in Data Labelling
Data labelling requires you to have a host of ethical considerations that necessitate care for fairness, equity, privacy, and transparency throughout the process.
Some of the elements that you may need to pay special attention to include:
Conclusion
Data Labelling assumes a lot of importance when it comes to AI development. It is your gateway to a future where machines comprehend, learn, and innovate with unprecedented accuracy. Make sure to implement the powerful processes of data labeling and witness the transformation it brings to the landscape of artificial intelligence.
FAQs
What are the common challenges in data labeling?
Addressing cost and time constraints, ensuring consistency, and handling ambiguous data are common challenges faced in the data labeling process.
How does data labeling impact machine learning models?
Accurate data labeling enhances the performance of machine learning models, providing a solid foundation for learning and decision-making.
Can automated data labeling replace manual labeling entirely?
While automated data labeling expedites the process, human annotators bring nuanced understanding, making a hybrid approach often preferred.
What role does data labeling play in autonomous vehicles?
Data labeling is essential in training self-driving cars to recognize and respond to diverse scenarios on the road.
Is data labeling only relevant for AI development, or does it have broader applications?
Data labeling extends beyond AI development, impacting industries like healthcare and contributing to more accurate analyses and diagnoses.
How can businesses benefit from meticulous data labeling?
Businesses benefit from improved AI capabilities, driving operational efficiency and fostering innovation through meticulous data labeling.














Add Comment